Context
This was originally a Confluence doc I wrote when I worked on a large product team tasked with several concurrent features (long live SuperApp!). Reposting it here so I remember what that was like, and what problems I thought could be avoided with a clearer process. Note, the references aren't linked to anything by design.
The famous scrum master / philosopher Jean-Paul Sartre once said,
Hell is other people’s processes.
He's right - process is hard. Too much process feels like bloat. Too little process feels like chaos. But there are benefits to having just the right amount of process.
This document should serve as…
- a playbook that enumerates the steps our team uses
- motivation for the process we have
- a set of references to process artifacts that help us plan and build the right thing
It is (and always will be) a work in progress. We should feel free to modify and reevaluate it as we learn what works for us.
What is the right amount of process?
Too little
- Fosters disconnect between product / engineers because we lack an agreement or shared understanding about what we’re building
- Doesn’t enable us to accurately predict the amount of time larger features will take, as the research has not been done ahead of time to reduce risk / document higher level design choices
- Makes it harder to onboard new engineers / improve bus factor, as institutional knowledge resides in individual team members instead of documentation and tickets
Too much
- Fills up our calendars and takes away from focused time
- Requires consensus between everyone on the team
- Leaves us unable to handle ad-hoc, out of schedule work that needs to be done quickly (for example, bugs, on call work, late additions to a sprint)
Goldilocks process
- Clarifies the requirements of any new feature work, which ensures we’ll have built the right thing when steps are said and done.
- Helps de-risk unknown work by doing focused research into new tools and services, finding working code examples to draw from, and by breaking apart investigations into smaller pieces. A 5 point spike ticket looks a lot scarier from a sprint planning perspective than a 1 point spike ticket and several 2 point tickets.
- Helps team planning and time budgeting by making sure the work we’re undertaking is documented enough to be actionable. The more experience we have, and more fine tuned our process gets, the easier it will be to break down larger features into discrete (and measurable) pieces of work, which makes it easier to plan for our roadmap.
- Distributes knowledge between team members who may not have exposure to different services and systems at Hopper. This keeps our bus factor high, and enables us to onboard new team members more easily.
- Ensures consistent execution of our plan for any feature work, and keeps the team on the same page. Without spike reviews and grooming, it’s much harder to guarantee that individual team members have the same understanding of a feature. This means that we may end up with functionally different code based on which engineers do a ticket.
- It also reduces the temptation to iterate on the design or reach a different understanding about the work in side channels, huddles, and post scrums without updating the current process artifacts (which result in a distributed or fractured understanding of the work the team will do).
- By all means keep doing those things! But try to keep new understanding of work in the latest process artifacts that are serving as the source of truth.
N.B. There is a necessary tension between process and lines of code!
Whatever doesn’t work, or feels onerous, should be done away with.
Stage agnostic goals
Keep the most relevant information as far “downstream” as possible
- It’s hard to jump up the chain of documents and keep establishing context / a proper understanding if the most current or correct information is scattered throughout the documents
Keep discussion and decisions (or a of record them) in text in the artifacts produced by this process, making it easier for...
- New team members to onboard and understand features
- Team members on PTO to catch up with work they missed
- Anyone looking backwards to have context that would otherwise be lost
Be transparent and vocal about when we shift from one stage to the next
- Has enough work and clarification been done at any stage to make the next stage actionable?
- Did all (or the majority of) team members get a chance to weigh in during spike review, closing any open questions?
By getting agreement that work is ready to progress from one stage to the next, we get a check-in that we have alignment about how to define, research, or build a feature successfully.
Stages of work definition
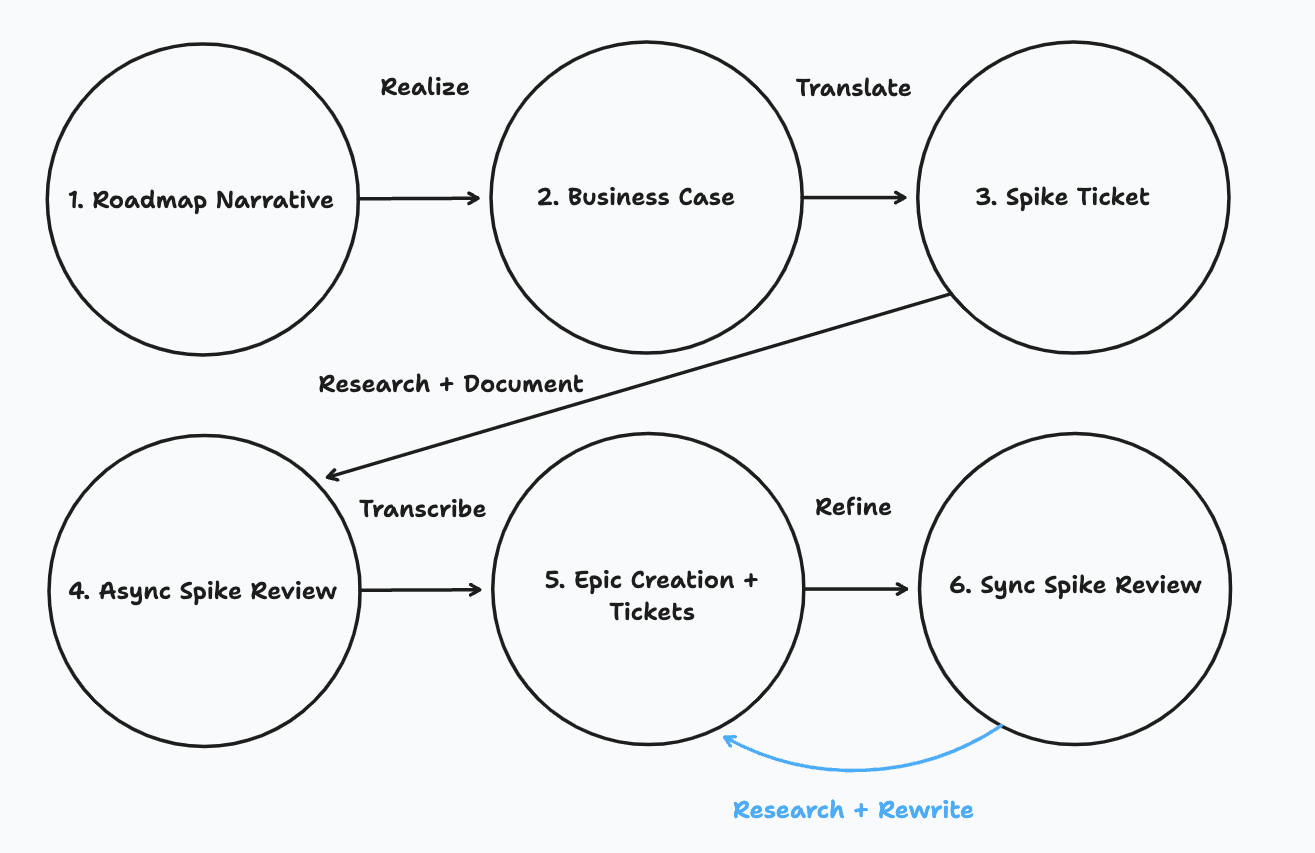
The journey from roadmap to actionable tickets
1. Roadmap Narrative (Business unit owner)
Roadmaps are an overarching plan that establish vision for a team (or set of teams). The document should address:
What are the product values we’re trying to support in this narrative?
For example, motivating the carousel and new user sale:
We believe that showing users dynamic and immediate offers in app upon install (and app open) will increase user retention and sales (and therefore LTV)
Reference - Building A Super App for Travel
2. Product Requirements Doc (Product owner)
The product owner should produce documents outlining specific features building towards that narrative. Each requirements document should answer questions such as…
- What does this feature look like?
- What are concrete use cases that we need to support?
- How can we validate that we’ve built the right thing?
- What business metrics could show that the feature is working as expected?
- What are possible future extensions of this work that seem likely?
- Is there anything we should actively avoid building towards?
The team can review the created document asynchronously as the PRD becomes more concrete. If there are any larger unknowns or tradeoffs, a synchronous meeting might be best.
Reference - Deal Drops MVP
3. Spike Ticket (Engineer)
An engineer should draft a spike ticket, which outlines the scope of the investigation. The spike ticket should describe:
- As a user (or service owner), what should the feature allow you to do?
- As a user (or service owner), what should the feature NOT allow you to do?
- Can we support the described use cases easily? Cheaply? Within systems we already control?
- What risk is involved with each possible solution? What tradeoffs should we be aware of?
The engineer should then record what they learned about possible approaches in a Confluence doc, covering:
- How is each piece of this feature constructed?
- What is additional complexity will each piece cost?
- How well does the proposed plan extend into future work?
- How does this solution align with our overall system design powering the product? Does this solution create technical debt or take short cuts?
- Does the solution impact or rely on other teams? Have we communicated any concerns or requirements to those affected?
- How can we validate that the feature we’re building is working and doing the right thing? What metrics can we use to determine success?
Their findings should be grouped into a single document and used to run a spike review.
Reference - Investigate Deal Drop homescreen carousel content
4. Spike Review - Asynchronous (Engineer)
Once the investigation is done for a new feature, the team asynchronously reviews the produced document, as a way of clearing up any large unknowns or red flags before going into a review. It’s important to give some time for the spike writer to address feedback before having a live meeting. The goal of a review should be to solidify any plans and discuss tradeoffs (with hopefully no surprises).
If the review goes well, and the team has a clear direction to proceed in because the above questions are addressed (from step 3), the engineer can proceed to the next step and create an epic and associated tickets.
There can still be some unknowns and associated spike tickets, but if there are still looming questions about the feasibility of a possible approach, it’s a strong sign that the best way forward may be to write a successor spike ticket and repeat steps 3 + 4.
Reference - Deal Drop Carousel MVP
5. Epic Creation (Engineer)
The team has alignment! The stakeholders have bought in! The last stage is to translate the above document into a Jira epic and associated tickets. The focus should be on keeping the most useful information as close to the Jira tickets as possible, as they are the latest source of truth and should capture any change in understanding about a ticket as it is refined and picked up.
The created tickets can be reviewed in bi-weekly grooming, using the slack planning poker bot, or at a post scrum if we need to build something quickly.
Some questions to ask during the process:
- Can we build the epic in phases to deliver value more cheaply or validate product understanding faster?
- How can we organize the tickets and epic so that small pieces are functional (and verifiable) as quickly as possible?
- Can we capture tradeoffs we’re accepting or any short-term solutions that we’re implementing that we’d like to address later on?
- Creating Jira tickets and referencing them in code leaves a well-lit path for rewrites later on
If there are other concerns around taking on technical debt or recording future work that won’t be done for MVP, record them while creating the epic and create associated backlog tickets.
Reference - Deal Drops - MVP
6. Spike Review - Synchronous (Engineer)
The team synchronously reviews the produced document, addressing smaller questions and ensuring alignment on the feature architecture / tradeoffs with different approaches. Live reviews tend to be the best way to have a conversation with product owners to understand drawbacks or tradeoffs for different solutions. If needed, the engineer may need to go back to Step 5 and refine tickets in the epic, but the changes should be minimal at this point since most alignment between product and engineering should already have happened during the async phase of the Spike Review.
At this point, the team has actionable tickets and a good estimate of the work to complete the epic. We can cycle back in for additional clarification as needed if requirements shift, but assuming no surprises, we can now focus on the release of the feature.
Once the epic and cards have been created and clarified, assign an "epic owner" as a point person for technical questions and estimated delivery of the epic. That engineer can also serve as a reference if cards need clarification, or the business case changes and we need to reevaluate.
We can add the work and owner to the sheet here, which posts a weekly thread on Mondays asking for a breakdown in our team channel using Workflow Builder.
As the epic is nearing completion, and we’re getting ready to ship the feature, we can use the following approach to rolling it out and regrouping with our learnings.
Stages of delivery
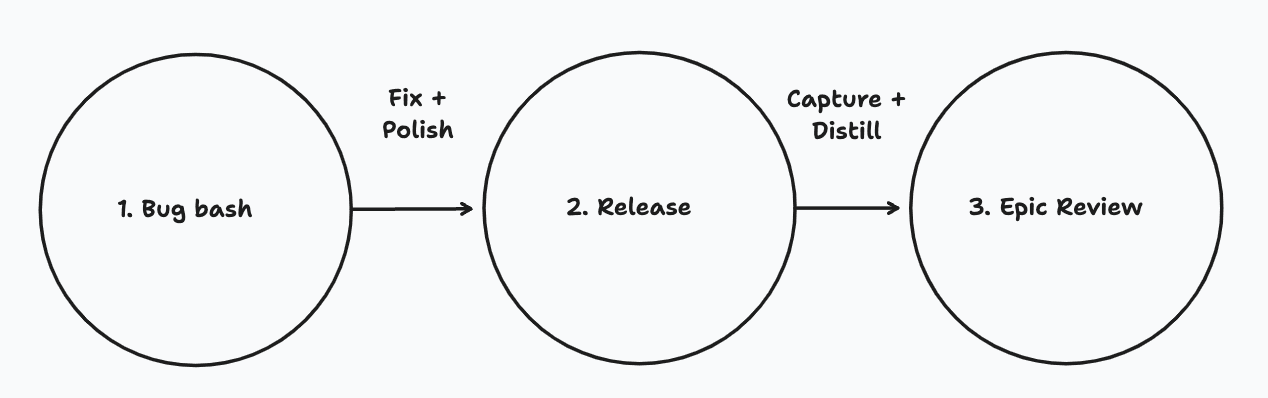
Approaching a release (with no surprises)
1. Bug Bash
Smoke test your new feature on staging and prod and across platforms (iOS and Android) using experiment gating. It can be helpful to have teammates who did not work on the feature to test, since they will have a more open mind and might be more likely to discover odd behavior.
2. Release
Gradually roll out the feature based on discussion with a PM. Carefully consider the following before ramping up exposure:
- What does the feature successfully being used look like? From a service (logs, datadog, statsd) perspective? From an Amplitude (tracking) perspective?
- How can exposure for the feature be rolled back? Can this be done safely / in place? What experiments are involved?
- What does the feature “running into trouble” look like?
- Is there monitoring and alerting defined that will catch this?
- Does the on call engineer know what to look for and how to debug? Are they empowered to turn the feature off if something suspicious happens outside of working hours?
3. Epic Review
You’ve shipped the thing! Users are interacting with the feature, or are relying on a different codepath / infrastructure. It’s useful to check back in before closing the epic to review the following:
- Were there any expectations that needed clarification from their original definition in the epic?
- Was anything learned “on the fly” or just in time? Could it have been avoided?
- Reexamine: Do the proposed business metrics show that the feature is working as expected?
- Does it positively impact user engagement with the product? Other impactful metrics?
- Reexamine: Possible next steps?
It’s important to capture the above diffs when the work is fresh in our minds, as things move quickly and it’s easier to share what was learned soon after the MVP is delivered. Granted, some experiments may take time to prove efficacy (or lack thereof).
Reference - Post-Launch Analysis: Air Repeat Incentives
Introspection and improvement
How can we tell when the process is working?
- We have fewer interruptions, surprise spikes, and changes in direction for feature work
- We build a backlog of ready tickets and epics that we can draw from at will, instead of filling our pipeline of prepared work just in time
- Team members trust "downstream" sources for the most accurate information, and find themselves context switching and slack thread unraveling less often
The Incentives team has had their own similar set of processes, and uses this folder (see the associated child pages) to keep a log of the features they’ve shipped over the past year. This is a good practice to adopt, and should provide an easy way to keep a reference to features we’ve implemented.
How can we tell if we’re still struggling?
- Our backlog remains relatively empty
- Tickets and spikes still feel brittle or prone to change
- Information isn’t reliably captured in process docs, leading to a diffused or fractured understanding of work
- Standups take more time as we rehash technical decisions and re-earn team buy in